Banco NoSql em Azure
Publicado por Alexandre Valente em Desenvolvimento, White Fox em 27/08/2020
Olá pessoal, continuando a série iniciada aqui, esta semana vou detalhar como migramos nossa API de controle de acesso de um banco de dados relacional Sql Server para um banco de dados NoSql, em Azure.
Os bancos NoSql estão sendo cada vez mais empregados em aplicações web devido à sua escalabilidade e menor custo. No entanto, seu uso exige uma série de cuidados e nem todos os domínios podem ser facilmente mapeados para utilizar este tipo de estrutura de dados. Domínios que tenham consultas complexas, que dependam de índices ou de extensas manipulações de entidades ou que utilizem um número elevado de transações em entidades diversas, podem ter uma alta dificuldade de mapeamento.
No nosso caso, escolhemos migrar a nossa API de segurança e autenticação. Ela foi uma boa opção por ser baseada em domínio pequeno, com ações pontuais (login, cadastro) e poucas consultas avançadas. Outro ponto favorável é que nosso sistema de segurança é multi-tenant, o que é relativamente fácil de implementar em um banco NoSql mas no mínimo problemático, em um banco relacional. Mais detalhes sobre isto abaixo.
Para a migração para NoSql no Azure, avaliamos utilizar o CosmosDb e o Azure TableStorage padrão. O interessante é que a forma de acesso e a estruturação de dados são praticamente iguais nos dois, o que muda é que no CosmosDb temos alguns recursos a mais (como por exemplo a remoção automática de registros por tempo), além de um melhor suporte para escalabilidade. Porém, enquanto o Azure TableStorage é bem barato (praticamente cobrança baseada em espaço alocado), o CosmosDb já é bem mais caro – cobrado por operações realizadas. No nosso cenário, o custo mensal do CosmosDb chegou perto do custo do Sql Server – cerca de USD 60 por mês, para o tamanho e uso do nosso banco. Como não temos grandes necessidades de contingência, acabamos escolhendo o TableStorage, e o seu custo mensal ficou inferior a 10 USD.
A ideia do uso de um banco NoSql usando o TableStorage é relativamente simples: um conjunto de tabelas identificadas por 2 tipos de índices, PartitionKey e RowKey. Alguns bancos suportam mais tipos de índices, mas no caso do Azure TableStorage, só temos estes 2 mesmo. Por ser uma aplicação muti-tenant, o identificador do Tenant é o PartitionKey, o que nos deixa somente a RowKey para identificar as entidades. Se partirmos de um mapeamento clássico relacional, o RowKey seria a Primary Key (PK) que identificaria cada instância. As Foreign Keys (FK) podem ser mapeadas por propriedades (colunas) na tabela, resolvendo os mapeamentos do tipo 1:N. O problema são chaves compostas e relacionamentos N:N, que exigem um esforço maior de mapeamento. A ausência de outros índices explica por que é complicado mapear um sistema com grande quantidade de relatórios e consultas, já que teríamos que criar uma estrutura para representar cada índice complexo e armazenar neles as RowKeys relativas às entidades que são identificadas pelo índice. Possível, mas complexo.
No nosso caso, simplificamos o modelo para poucas entidades (ver diagramas abaixo, do modelo original e do NoSql), cada um identificado pela sua RowKey. Tínhamos algumas necessidades de relacionamentos N:N, como por exemplo a de aplicações e de permissões em usuários. Para estes casos, criamos uma coluna na tabela do usuário contendo a serialização da coleção destas entidades. Estas colunas são carregadas e deserializadas quando a entidade é trazida da TableStorage.



Para fazer a manutenção das tabelas no Azure TableStorage, sugiro usar o Azure Storage Explorer. É uma aplicação bem simples mas que permite efetuar todas as operações necessárias.
Outro ponto que é bem diferente do modelo relacional é carga (load) das entidades. No modelo relacional, o típico é mapear todas as colunas para o objeto e carrega-lo de uma vez do banco de dados. Como no NoSql podemos ter muitas colunas que são utilizadas como repositório (como as de coleções, por exemplo), carregar todas as colunas seria um custo elevado. Assim, tipicamente, a cada operação de acesso ou de salvamento, somente as colunas afetadas são solicitadas ou alteradas.
Para facilitar a persistência das entidades, criamos um pequeno framework com as operações básicas. Denominamos “entidade raiz” aquelas que estão ligadas diretamente ao Tenant, tais como Application, User ou RefreshToken (ver modelo acima). As entidades raiz são carregadas diretamente pelo RowKey e pelo TenantId específico – ver trecho de código abaixo. As demais entidades são subordinadas a uma entidade raiz (como Roles ou Permissions) nelas, a PartitionKey é sempre a chave da entidade Raiz e a RowKey é a sua chave específica – ver abaixo. Fizemos também métodos para carregar ou salvar objetos na TableStorage que permitem especificar as colunas necessárias para cada operação. Finalmente, fizemos também métodos para facilitar a serialização/deserialização de coleções quando são repositórios em colunas.
public Task<T> LoadTenantRootEntity<T>(Guid id, params string[] columns)
where T : TableStorageEntity, new() {
return LoadTenantRootEntity<T>(GuidToString(id), columns);
}
public async Task<T> LoadTenantRootEntity<T>(string id, params string[] columns)
where T: TableStorageEntity, new() {
var retrieveOperation = TableOperation.Retrieve<T>(tenant.Identifier, id, columns.Length > 0
? columns.ToList()
: null);
var result = await Table<T>().ExecuteAsync(retrieveOperation);
return result.Result as T;
}
Código para carga de entidade raiz com TenantId
protected async Task<IList<T>> LoadAll<T>(string partitionKey, params string[] columns) where T : TableStorageEntity, new() {
var query = new TableQuery<T>().Select(columns).Where(TableQuery.GenerateFilterCondition("PartitionKey", QueryComparisons.Equal, partitionKey));
TableContinuationToken continuationToken = null;
var results = new List<T>();
do {
var result = await Table<T>().ExecuteQuerySegmentedAsync(query, continuationToken);
continuationToken = result.ContinuationToken;
results.AddRange(result.Results);
} while (continuationToken != null);
return results;
}
Código para carga de entidades filtradas por Partition Key
O resultado ficou bem interessante. As operações básicas ficaram bastante simples e o tempo de resposta das operações ficou muito bom. Em vários cenários, temos um desempenho bem superior ao modelo relacional – nas operações de login, por exemplo, tivemos um ganho muito expressivo. A implementação de multi-tenant ficou muito mais simples do que seria em um modelo relacional, graças aos índices de PartitionKey.
A conclusão é que o banco NoSql é uma boa alternativa pra vários cenários, mas nem sempre é algo simples de se modelar. É um mecanismo de persistência muito mais barato, em termos de Azure, quando comparado a um banco Sql Server. E, dependendo da implementação, é mais rápido e mais facilmente escalável do que um Sql Server tradicional. Como tudo em TI, é conveniente pesar os prós e contras antes de partir para uma linha NoSql. E sempre fazer uma prova de conceito antes de iniciar a migração. Mas tenho certeza que, se bem construído, um sistema com banco NoSql pode ser uma melhor opção do que a linha relacional padrão, em vários cenários.
Fiquem à vontade para comentar ou se tiverem alguns outros cenários de aplicações NoSql e quiserem trocar uma ideia. O próximo post será sobre o Azure Api Management. Até lá!
Azure DevOps
Publicado por Alexandre Valente em Desenvolvimento, White Fox em 16/08/2020
Oi pessoal! Iniciando a sequência de artigos sobre tecnologias e plataformas citadas aqui, vou começar pelo básico: configuração de ambiente DevOps no Azure.
Embora DevOps esteja em adoção crescente há vários anos, sua adoção em larga escala só se tornou possível com o foco da Microsoft no Azure DevOps. A migração do antigo TFS para o GIT, a integração de todas as ferramentas em https://dev.azure.com/[suaempresa] e a automatização via pipelines de CI (Continuous Integration) e CD (Contiunous Deploy) tornou todo o processo simples de ser implementado.
Bom, vamos assumir que estamos começando do zero e montar um ambiente de DevOps no Azure e mostrar todos os passos necessários. O único requisito é ter uma assinatura Azure válida para se registrar os artefatos.

O primeiro passo é criar a empresa no DevOps. Isto pode ser feito em https://dev.azure.com, bastando seguir os tutoriais. O primeiro artefato que temos que criar é o projeto inicial. O termo projeto aqui pode gerar confusão, pois há a tendência de se tratar um projeto como projeto Visual Studio. Mas, na nossa experiência, é mais produtivo tratar um projeto DevOps como sendo todo o contexto de um cliente. Assim, todas as solutions, projetos visual studio, artefatos etc. relativos a um cliente normalmente são armazenados em um único projeto DevOps. Abaixo a tela de gestão do projeto no Azure.

Dentro de um projeto podemos ter múltiplos repositórios GIT. Usualmente é criado um repositório para cada projeto do tipo bibliotecas, serviços ou sistemas. Já vi algumas defesas de se ter um repositório único para tudo (nós até já chegamos a usar este formato por algum tempo), mas isto complica a geração dos pipelines de CI. Assim, preferimos usar repositórios separados mesmo. Como é típico em um repositório GIT, temos o branch master, que armazena a versão de produção e branchs de desenvolvimento, usados para gerar as versões para testes e homologação. Em organizações que precisam de um compliance mais forte, pode ser criada uma política que impeça o commit direto no branch master, exigindo um pull request do desenvolvimento para ele. Este pull request pode também exigir aprovadores, o que garante um alto controle do que segue para o master. Claro que isto tem um impacto negativo em produtividade. Como na White Fox o objetivo é agilidade, nós não temos estes controles ativados.
Outro ponto importante para configurar no projeto é um feed de artefatos (último elemento na barra lateral esquerda). Este feed tem como finalidade a publicação dos pacotes Nuget das bibliotecas utilizadas naquele projeto DevOps. Embora o feed seja para uso interno (ele exige autenticação), dá para se configurar acesso para outros projetos ou mesmo para outras empresas. Na White Fox, estamos migrando todos os nossos pacotes Nugets de um servidor público para um feed de projeto, simplificando nossa infra e facilitando o processo de CI/CD.
Com o feed de artefatos criado, o próximo passo é criar os pipelines de CI para cada projeto utilizado. Ao se criar um pipeline, temos duas opções: utilizar pipelines clássicos ou baseados em arquivos yaml. Em geral, o pipeline clássico atende os cenários típicos, enquanto que os baseados em arquivos yaml permitem uma maior flexibilidade e customização das tarefas. A figura abaixo mostra a tela de criação. Inicialmente se escolhe o repositório de origem e aí basta seguir o assistente que vai gerar o arquivo yaml. Para escolher criar um pipeline clássico, basta usar o link no final da tela.

Usualmente nossos pipelines de CI fazem as seguintes tarefas: 1 – baixar artefatos nuget; 2 – compilar projetos; 3 – executar testes unitários; 4 – publicar artefato no próprio pipeline. Abaixo um pipeline clássico web e um de arquivo yaml.


Um alerta: apesar da Microsoft já ter recentemente permitido o desenvolvimento de Azure Functions em .NET Core, ainda não é possível fazer um pipeline para deploy deste tipo de Function. Se alguém tiver este cenário, é necessário por enquanto ainda fazer uma publicação manual – o que não é nada complexo, dá pra fazer direto do Visual Studio. Creio que em breve este tipo de pipeline também estará disponível.
Após termos os pipelines de CI funcionando, o último passo é criar os pipelines de release – CD. Usualmente o pipeline de release é criado baseado em um trigger de pipeline de CI bem sucedido. O pipeline de CD simplesmente baixa os artefatos e, caso seja uma aplicação web, publica direto no Web App; caso seja um Nuget, publica direto no feed de artefatos. Abaixo exemplos de pipelines Nuget e web app. Abaixo um pipeline web.

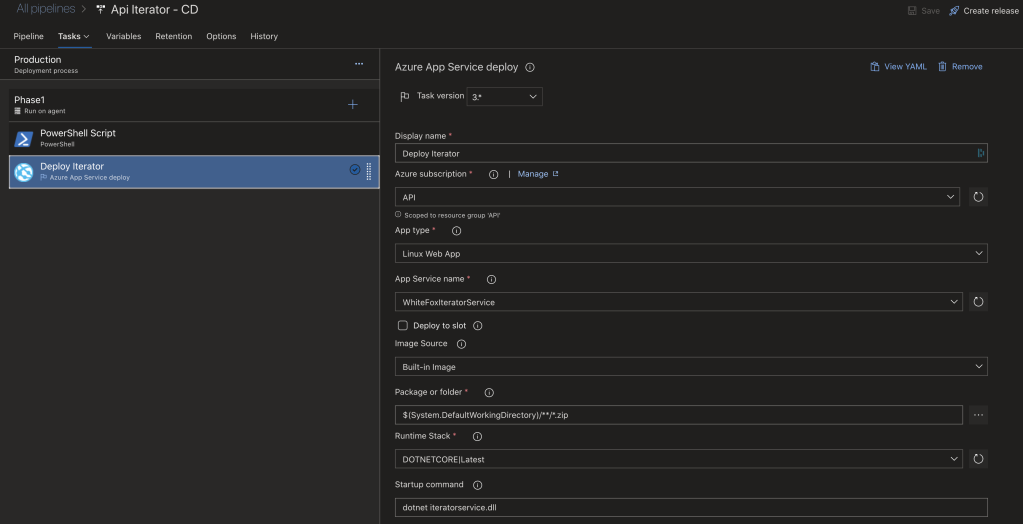
Finalizando os pipelines de release, voi-la, temos todo o nosso ambiente operacional em DevOps CI/CD. Um commit no master irá iniciar o pipeline de CI, que irá compilar, testar e deixar pronto pra publicação. Quando o CI finalizar, o pipeline de CD irá pegar os artefatos e automaticamente publicar no servidor Nuget ou direto no Web App.
Um último item que gostaria de apontar é sobre notificações. O DevOps por padrão já envia e-mails no sucesso ou falha do CI para quem fez o commit. É tranquilo também configurar o envio de e-mails para um grupo no caso de sucesso ou falha – dá até pra criar automaticamente workitems em falhas, se for desejado. No nosso caso, como somos usuários do Microsoft Teams, nós preferimos receber as notificações por ele.
Existe um bot público chamado Azure Pipelines – basta buscar em aplicativos no Teams. Ao instalar, ele permita que façamos assinaturas dos pipelines e publiquemos notificações em canais específicos. Assim, toda vez que um Release é feito com sucesso, todos nós da White Fox recebemos uma notificação no Teams automaticamente.


É isto pessoal. Uma vez configurado, o Azure DevOps funciona impressionantemente bem. Todos os nossos artefatos principais já estão em CI/CD e isto tem poupado muito tempo nosso em testes e deploys. Recomendo a qualquer empresa de software que passe a usar o Azure DevOps com CI/CD, se ainda não o faz!
No próximo artigo vou falar um pouco de services .net core usando NoSql. Até breve!
Casa de Ferreiro…
Publicado por Alexandre Valente em Desenvolvimento em 09/08/2020
Olá pessoal! Como estão de quarentena, com quase 5 meses de isolamento? Neste tempo muita gente aproveitou para aprender novas habilidades como cozinhar, pintar etc. No meu caso, resolvi empregar o tempo em algo que estávamos precisando fazer há muito tempo. Como prega o ditado, “casa de ferreiro, espeto de pau”, os sistemas utilizados internamente na White Fox já tinham passado da hora de serem atualizados. Ainda tínhamos sistemas em tecnologia antiga, hospedados em formatos que não recomendaríamos para ninguém.
Então, de março para cá, gastamos muitas horas para atualizar 100% do nosso parque tecnológico. E não só atualizar, aproveitamos para colocar tudo no estado-da-arte da que existe hoje. Como já citei várias vezes, estar atualizado é parte fundamental de nosso trabalho. Mas, principalmente por falta de tempo, a gente foca em empregar novas tecnologias e práticas nos nossos clientes e deixa de lado os nossos sistemas internos. Bom, não mais! Depois destes meses, estamos novamente orgulhosos de nossos sistemas! Eles estão utilizando o que há de melhor e mais moderno, tanto em boas práticas quanto em tecnologia. Neste artigo, vou fazer uma sinopse de como ficou a estrutura completa e, nas próximas semanas, detalhar melhor algumas das tecnologias e plataformas empregadas.
Para começar, fizemos uma refatoração e uma separação de camadas, isolando todas as nossas regras de negócios em APIs REST. Estas foram hospedadas em um API Gateway com o uso o Microsoft Azure Api Gateway – que é fantástico, com certeza teremos um artigo só para ele. O Api Gateway age como fachada para a cada API, gerenciando o acesso através de assinaturas e implementando as regras que se fazem necessárias. A figura abaixo mostra o uso do nosso API em uma semana normal.

Aproveitamos que queríamos ter um caso de estudo de banco de dados NoSql e convertemos todo nosso sistema de autenticação e segurança para usarmos um banco de dados deste tipo. Fizemos testes com o Cosmos Db mas acabamos utilizando mesmo o Azure TableStorage padrão. O resultando ficou muito bom, detalho isto em artigo futuro.
Cada uma das APIs foi documentada em swagger usando o swaggerhub – que é completamente integrado ao Azure Api Gateway. Todas as APIs foram implantadas com o uso do Microsoft DevOPs, com Continuous Integration (CI) e Continuous Delivery (CD). Assim, após o commit, todos os testes unitários são automaticamente executados e, quando aprovados, atualizados diretamente no API Gateway, ficando disponível para aplicações web, móveis ou outras.
O uso de APIs Rest nos sistemas Windows e Web ficou bem simples com o uso do Unchase Open API Connected Service (que pode ser instalado no Visual Studio). Ele se usa das especificações swagger para gerar um proxy local, similar à uma referência WCF. O primeiro sistema que atualizamos foi o sistema interno de gestão, com o uso de um site Angular 10. Um ponto que tivemos cuidado de implementar no sistema web foi a utilização de chamadas de APIs de ação de forma 100% assíncrona. Isto melhora o tempo de resposta para o usuário e a escalabilidade do sistema. Mais sobre isto em artigos futuros

O segundo sistema que atualizamos foi o nosso aplicativo Windows. Ele é utilizado por alguns desenvolvedores que preferem ter algo sempre ativo no desktop. Com o uso do Unchase, também foi super simples migrá-lo para utilizar o Api Gatway.
Agora a “jóia da coroa” deste período foi a Lana. Já éramos usuários do Microsoft Teams há um bom tempo, e tínhamos ouvido que o Microsoft Bot Framework 4 estava valendo a pena, especialmente integrado ao Teams. Assim, mergulhamos a fundo e o resultado foi excelente. Construímos um bot, chamado Lana, para o Teams da empresa, que age como interface para todas as nossas APIs. E por ser um bot, comunicamos em linguagem natural escrita de maneira rápida e intuitiva. O resultado ficou tão bom que poucos ainda usam o sistema web ou aplicação Windows. Com certeza farei um artigo sobre a Lana.

Tudo tem lados positivos e negativos e esta pandemia não foi diferente. Sem ela não teríamos todo este tempo disponível para atualizar e avançar nosso conhecimento sobre as mais recentes plataformas e tecnologias. Podemos afirmar com certeza que agora em casa de ferreiro, temos um espeto de aço inoxidável da melhor qualidade! Nos próximos artigos detalho um pouco mais cada um destes componentes. Até breve!
White Fox – 10 Anos
Publicado por Alexandre Valente em Desenvolvimento em 04/05/2020
10 Anos! Nada mais certo do que a frase “o tempo voa”. Ainda me lembro quando imaginamos criar uma empresa que valorizasse a qualidade ao invés do simples lucro de uma fábrica de software (ver White Fox – O Início). Não que o lucro não seja importante, afinal nenhuma empresa sobrevive sem ele; mas sim, tê-lo como consequência de um trabalho bem feito. Sempre nos definimos mais como um ateliê de software do que uma fábrica. Construímos sistemas considerando a particularidade de cada cliente, com o objetivo de obter a melhor relação custo/benefício e com a melhor qualidade possível.
E fazer software de qualidade é de fato complicado. Já era assim há 10 anos, quando a arquitetura MVC estava no auge (ver Engine MVC) e as bibliotecas de mapeamento Objeto Relacional – ORM, como o Microsoft Entity Framework, estavam ficando maduras (ver Produtividade – Camada de Domínio). Nesta época, o desafio era ter sistemas com bom desempenho e fáceis de manter, contemplando todas estas camadas sobrepostas.
E, 10 anos depois, continua complicado. Se por um lado as ferramentas evoluíram e temos uma disponibilidade incrível de recursos (como os recursos PaaS disponíveis no Microsoft Azure ou Amazon Cloud), o ambiente está muito mais complexo. As aplicações web tem agora uma grande capacidade de processamento no cliente (com Angular8+ por exemplo) e temos toda uma gama de aplicativos-cliente nas mais diversas plataformas. Os sistemas devem ser expostos através de APIs para suportar todo este ecossistema, garantindo desempenho e disponibilidade. O volume de transações exige um processamento assíncrono, orquestrado por barramentos de serviços que muitas vezes integram vários fornecedores em locais físicos diferentes ou em cloud. Tudo isto mantendo os princípios básicos de custo razoável, bom desempenho e grande manutenabilidade.
Para nós, da White Fox, é um prazer fazer parte destas evoluções tecnológicas. Eu (e alguns dos sócios mais antigos) começamos a viver a evolução de sistemas distribuídos desde a época do Microsoft DCOM, há muito tempo – melhor nem fazer as contas! Por ter esta visão histórica, percebemos que, embora a tecnologia mude rapidamente, os princípios básicos do desenvolvimento de software permanecem inalterados. Código simples, legível e de fácil manutenção continua sendo o pilar principal de qualquer sistema. Arquiteturas leves, escaláveis desde sua concepção, que possam ser adaptadas rapidamente são cada vez mais importantes. Software Design Patterns continuam fazendo a diferença na hora de construir microserviços de qualidade para exposição em API Gateways. Manutenabilidade e testabilidade faz toda a diferença no custo a médio prazo e na gestão baseada em DevOps.
E a única certeza que temos é que esta evolução vai continuar, e que vai ser cada vez mais rápida. A cada ano, teremos mais recursos e mais tecnologia disponível para construção de sistemas. Mas temos também a certeza que nós, da White Fox, estamos prontos para os próximos anos. Continuaremos sendo os artesãos que irão transformar todo este potencial em sistemas relevantes para nossos clientes. Sempre com o objetivo trazer para eles mais produtividade, mais inovação e mais sucesso em seus negócios. Quem venham os próximos 10 anos!
Produtividade – Camada de Domínio – Revisão
Publicado por Alexandre Valente em Desenvolvimento, White Fox em 15/11/2016
Olá pessoal! Em 2009 (nossa!), eu escrevi uma série sobre produtividade, onde a ideia era colocar as técnicas que usamos no nosso dia a dia na White Fox para o desenvolvimento de sistemas. Embora os princípios continuem todos válidos, a tecnologia evolui. Assim, a ideia é fazer uma série atualizando cada uma destas postagens, de acordo com a linha que usamos atualmente.
A primeira delas é sobre a camada de domínio. Nesta camada, tivemos um amadurecimento de tecnologias que hoje tornam mais fácil a vida de quem precisa utilizar um ORM. No entanto, cresceram as dúvidas e questionamentos teóricos sobre que mecanismo utilizar para acessar dados. A linha do NoSQL ganha força e é o padrão para muitos tipos de sistema, especialmente agora, com um uso maior de sistemas baseados em PAAS como Azure ou Amazon.
Mesmo para os sistemas com domínio orientado à objeto e banco SQL, há vários questionamentos sobre se faz sentido o uso de um ORM. Existem várias pessoas que apontam os problemas de se tentar usar um (exemplo aqui) e nós mesmos já sofremos bastante com problemas oriundos deste mapeamento; recentemente fiz até um post sobre isto. Existem até aqueles que questionam o uso de OO em si, ou os que estão partindo para linguagens funcionais como o F#.
Mas, para quem usa bancos SQL, o uso de ORM ainda é a melhor alternativa. Claro que isto pode gerar problemas e definitivamente há casos em que é melhor não usar. Mas em termos de produtividade e manutenabilidade, ainda é a melhor opção. Temos usado consistentemente em todos nossos sistemas e, salvo algumas exceções em pequenas áreas, o resultado tem sido excelente.
Em termos de tecnologia, temos mais alternativas do que o nHibernate, que reinava absoluto em 2009. Vários pequenos frameworks como o nPoco tem um uso mais difundido. E o Entity Framework (EF) da Microsoft amadureceu e hoje compete de igual para igual com o nHibernate. Nossos sistemas usam predominantemente o nHibernate, até porque temos grandes sistemas em operação que começaram com ele. Mas, para novos sistemas, estamos preferindo o EF, principalmente por sua excelente integração com o LINQ do .NET. Utilizamos o database-first, com a declaração fluente de mapeamento e ainda usamos arquivos .TT para gerar todos os artefatos como repositórios, containers etc.
Quando o sistema é muito pequeno ou quando desempenho é um requisito especialmente severo, criamos uma versão de ORM que utiliza stored procedures diretamente. É claro que isto tem sérias restrições, mas para estes tipos de sistemas conseguimos otimizar removendo quase todas as camadas e utilizando o máximo poder do servidor SQL.
Para tentar minimizar a manutenção, criamos bibliotecas comuns a todos os ORM que utilizamos. Assim, trabalhar em sistemas que usam ORMs diferentes é uma experiência similar da camada de negócios para cima. Temos caso até de, em um mesmo sistema, termos diferentes áreas usando diferentes ORMs. Claro que nestes casos, temos que ter uma camada de comunicação para garantir integridade, muitas vezes baseadas em microservices.
Em termos de regras de negócio, continuamos utilizando um modelo anêmico. Esta continua sendo uma guerra santa na comunidade técnica, mas no nosso caso, não temos como negar todos estes anos de sucesso. O modelo anêmico facilita o isolamento de regras de negócio, simplifica o treinamento de novos desenvolvedores e a manutenção de todos os nossos sistemas. E estamos ainda colhendo alguns bônus adicionais, pois este tipo de modelo tem facilitado o isolamento de porções de regras de negócio para encapsulamento em micro-serviços, o que nos tem permitido evoluir nossos sistemas mais antigos de maneira viável. E, na inevitável migração para a nuvem, que deve ocorrer ao longo dos próximos anos, vamos poder também fazer uso de recursos avançados como Azure Servless Functions, graças a esta arquitetura.
Nos próximos posts devo comentar sobre a camada de interface, onde tivemos as maiores mudanças e as maiores evoluções tecnológicas. Até lá!
ORM e Concorrência
Publicado por Alexandre Valente em Desenvolvimento, White Fox em 22/09/2016
Olá pessoal! Há algum tempo atrás sofremos um pouco na manutenção de um dos grandes sistemas da White Fox. Quero compartilhar a experiência para que outros não tenham que passar pelas mesmas dificuldades!
Só relembrando, conforme meu antigo post sobre a camada de domínio, nós utilizamos ORM (nHibernate ou Microsoft Entity Framework) para fazer o mapeamento de entidades para o banco de dados, de modo a abstrair os mecanismos de persistência. Isto tem funcionado muito bem para nós – utilizamos ORM em praticamente todos nossos sistemas de maior porte há mais de 10 anos com sucesso. Claro que por mais que tentemos compartimentalizar, ao longo do tempo os domínios acabam crescendo. Hoje temos sistemas com domínios de mais de 300 objetos e milhares de linhas de código de regras de negócio.
Pois bem, neste sistema em particular, começamos a perceber há algum tempo, problemas de dados somente no ambiente de produção. Valores que aparentemente ficavam errados do nada. E, obviamente, nenhum destes problemas aparecia em homologação ou durante a execução de testes unitários. Claro que, como todo acidente, nenhum erro mais grave tem uma única causa. Neste caso em específico, também temos uma sequência de eventos que levaram à falha. Olhando agora, são até que óbvios, mas gastamos um bom tempo no diagnóstico e solução.
O primeiro componente começou com uma prática usual de ORM. Quase todos possuem uma proteção para evitar que a persistência ocorra em um registro que foi alterado por outrem. Por exemplo, se o ORM carrega um objeto em memória, faz nele alguma alteração e ao salvar, detecta que o registro no banco não é o mesmo de quando o objeto foi carregado, ele gera uma exceção. Porém, este mecanismo deixa tudo lento, já que para implementá-lo, o ORM acaba tendo que fazer uma query a cada UPDATE. E como usamos transações, os LOCK do banco de dados acabam garantido a atomicidade da operação, assim esta proteção acaba ficando redundante. No nosso caso ela sempre é desligada.
O segundo componente é a criação de campos para contadores ou totalizadores. Sim, claro, isto é algo que se deve evitar, especialmente como atributo de uma entidade de domínio. Por exemplo, colocar o total de uma nota fiscal como atributo ao invés de calcular o total através da soma de seus elementos. Usualmente evitamos isto, mas, em algumas entidades, calcular o valor toda hora pode ser complicado, seja porque existe alguma regra de negócio muito complexa envolvida ou um número muito grande de elementos para compor o total. Então, em algum momento, alguém resolve que manter o totalizador oferece uma melhor razão custo/benefício. Obviamente que se usam transações para manter os totais e se criam testes unitários para garantir que os totalizadores funcionam em todos os cenários.
O último componente do problema é a concorrência. Dificilmente teste unitários são criados para simular uma carga de múltiplos usuários simultâneos, pela complexidade de se simular este tipo ambiente. Assim, no teste unitário, quase não há concorrência. Porém, em produção os nossos sistemas são usados por centenas de usuários simultâneos. Apesar dito, tipicamente um usuário faz transações em uma única grande “entidade” por vez (p. ex., vendendo um produto). Assim, mesmo vários usuários em paralelo dificilmente mexem na mesma entidade, simultaneamente, ao mesmo tempo.
Mas as exceções é que fazem a coisa desandar. Se desligamos a proteção de dados alterados, usarmos totalizadores em entidade e usuários alteram esta mesma entidade quase ao mesmo tempo, temos o nosso problema acontecendo! Para detalhar, vejam a figura a seguir. Imaginem 2 processos executando em paralelo, em tempos muito próximos um do outro.

Em um momento 1, ambos carregam a mesma entidade em memória, uma delas com um atributo totalizador. Como neste momento ainda não houve nenhuma transação, ambos conseguem carrega-la simultaneamente, e ambas possuem o mesmo valor para o atributo. No momento 2, ambos fazem algum processamento em que vão atualizar o campo totalizador. No momento 3, o primeiro processo abre uma transação, salva os objetos e faz o COMMIT. O segundo processo tenta fazer o mesmo, porém como o primeiro fez o LOCK, ele é bloqueado e fica em espera. Se não cair por timeout, quando o primeiro processo acabar, ele é liberado, começa sua transação, salva os seus objetos e faz o seu COMMIT. Como não há proteção para alteração, ele não vai perceber que o objeto foi alterado pelo primeiro processo e vai completar a ação achando que tudo correu bem.
Mas percebam que o segundo processo partiu objetos com totalizadores incorretos! Como o ele carregou os objetos no mesmo momento que o primeiro processo, ele não vai contemplar as alterações feitas por ele e vai salvar um total incorreto. Um exemplo, ambos carregam um atributo com um valor total de 10, ambos somam 1, o primeiro salva 11, o segundo também vai salvar 11, incorretamente!!!
Uma vez diagnosticado, o problema também não é simples de resolver. Não há solução trivial com o uso de ORM. Soluções como ativar a proteção de alteração, usar LOCK pessimista ou usar singletons, possuem pontos extremamente negativos e foram rejeitadas por nós. No final, a solução que adotamos foi, para campos totalizadores, ignorar totalmente o ORM e ir direto ao banco. Fizemos isto com o uso de um repositório especialmente projetado para este fim e com o uso de stored procedures para garantir que as alterações sejam feitas com as proteções adequadas. Esta solução conseguiu até mesmo melhorar o desempenho da aplicação, pois evitamos a manipulação de totais pelo ORM e transferimos todo o trabalho para o banco. O ponto negativo é que o sistema fica bem mais complexo de manter e uma porção das regras de negócio saiu do domínio e foi para o banco. Mas de todos os males possíveis, este foi o que achamos de menor impacto.
Moral da história é: conheça seu ORM, evite a todo custo campos totalizadores e, se tiver que usá-los, não se esqueça que poderá ter graves problemas em um ambiente com concorrência.
Este e outros eventos tem nos feito repensar o uso de ORM como um absoluto. Acho que já está na hora de refazer minha série sobre produtividade, atualizando-a com as tecnologias e práticas que temos adotado nos últimos anos. Tudo muda e TI muda ainda mais rápido. Acho que até que conseguimos ter uma relativa estabilidade nos nossos ambientes por muito tempo. Mas obviamente a evolução é necessária e tem hora que mudar paradigmas é essencial para mantermos nossa produtividade. Mais sobre isto em breve!
Até a próxima!
Arquitetura de Microservices utilizando o Microsoft SQL Service Broker – Parte 3 – Final
Publicado por Alexandre Valente em Desenvolvimento, White Fox em 22/11/2015
Olá! Antes de iniciar a última parte desta série, uma notícia boa: a White Fox se tornou parceiro Microsoft Silver em Application Development e Gold em Devices and Deployment. Além do reconhecimento, a parceria com a Microsoft é importante para dar uma visibilidade maior para a White Fox e nos permitir acesso a muito mais recursos para nosso processo de desenvolvimento. Obrigado a todos que nos ajudaram durante a certificação! Em 2016 a White Fox deve focar mais no Microsoft Azure, sempre buscando trazer o melhor da tecnologia para nossos clientes com a melhor relação custo/benefício.
No último post, mostramos a estrutura montada no SQL Service Broker para suportar nossa arquitetura de Microservices. Nesta última parte vamos mostrar as estruturas em .NET que suportam o Thin Client (cliente) e os executores. Como estamos montando uma arquitetura expansível, criamos então uma classe estática, utilizando um container Microsoft Unity, que chamamos de ServiceBus, para registrar cada cliente e executor. O código dela pode ser visto abaixo.
public static class ServiceBus {
private static IUnityContainer iocCcontainer;
private static bool isInitialized;
public static void InitializeSql(string connectionStringName) {
isInitialized = true;
iocCcontainer = new UnityContainer();
iocCcontainer.RegisterInstance(typeof(IStorage), new SqlStorage(connectionStringName));
}
public static T GetService<T>() where T: class, IService {
if (!isInitialized) throw new ServiceBusNotInitializedException();
return iocCcontainer.Resolve<T>();
}
public static void RegisterService<T>(Type type) where T : class, IService {
if (!isInitialized) throw new ServiceBusNotInitializedException();
iocCcontainer.RegisterType(typeof(T), type);
}
public static void RegisterComponent<T>(T instance) where T : class, IComponent {
if (!isInitialized) throw new ServiceBusNotInitializedException();
iocCcontainer.RegisterInstance(typeof(T), instance);
}
}
As interfaces IService são os serviços de mensageria, tanto do cliente quanto do executor. As interfaces de IComponent são para classes que são responsáveis por implementar as regras de negócio do executor. Abaixo um exemplo de uso do ServiceBus, onde o ResultMessagesReceiver (que implmenta IReceiver) é o responsável por processar as mensagens de retorno recebidas e o ClienteService (que implementa IClientService) é o Thin Client.
ServiceBus.InitializeSql("ServiceBroker");
ServiceBus.RegisterComponent<IReceiver>(new ResultMessagesReceiver());
ServiceBus.RegisterService<IClientService>(typeof(ClientService));
Criamos também um ServiceBase, que é usado por executores e clientes para implementar as rotinas principais de processamento de mensagens. O código está abaixo. É praticamente um loop onde as mensagens são lidas do SQL Server, dentro de uma transação, e processadas. Em caso de qualquer problema, a transação pode ser desfeita e a mensagem permanece lá. É importante notar que caso aconteçam muitos rollbacks em sequência, o SQL Server desativa a Queue (isto nos causou alguns problemas de debug!). Neste caso, a Queue deve ser reativada antes que outras mensagens possam ser lidas.
protected void ProcessMessages(int maxMessages) {
var counter = 1;
do {
if (++counter > maxMessages) break;
storage.BeginTransaction();
try {
var message = storage.ReadMessage(endPoint);
if (message == null) {
storage.Commit();
break;
}
if (string.IsNullOrEmpty(message.Handle)) {
storage.Commit();
break;
}
if (initiator && message.MessageType == EndMessageType) {
storage.EndConversation(message.Handle);
storage.Commit();
continue;
}
if (message.MessageType == ErrorMessageType) {
// todo: logar o erro
storage.EndConversation(message.Handle);
storage.Commit();
continue;
}
message.Date = DateTime.Now;
if (!ProcessMessage(message)) {
storage.Rollback();
break;
}
if (!initiator) storage.EndConversation(message.Handle);
storage.Commit();
}
catch (Exception) {
storage.Rollback();
throw;
}
} while (true);
}
Abaixo está a parte relevante do código que implementa o storage do SQL Server. Optamos por simplesmente encapsular chamadas a stored procedures que ficam no banco de dados utilizado para as filas de mensagens. A seguir estão também as 3 procedures de leitura, envio e final de conversação.
public string SendMessage(EndPointConfiguration endPoint, string data, string conversationHandle = null) {
var parameters = new Parameters()
.Add("initiatorService", endPoint.Initiator).Add("targetService", endPoint.Target)
.Add("contract", endPoint.Contract).Add("messageType", endPoint.MessageType)
.Add("data", data);
if (!string.IsNullOrEmpty(conversationHandle))
parameters.Add("handle", conversationHandle);
StoredProcedureFacility.ExecuteScalar<string>(connectionStringName, "SendMessage", parameters)
}
public Message ReadMessage(EndPointConfiguration endPoint) {
var root = StoredProcedureFacility.GetXml(connectionStringName, "ReadMessage", Parameter.Create("queueName", endPoint.QueueName));
return new Deserializer<Message>(root)
.Property(m => m.MessageType, "mt")
.Property(m => m.Contents, "data")
.Property(m => m.Date, "dt")
.Property(m => m.Handle, "ch")
.Instance();
}
public void EndConversation(string handle) {
StoredProcedureFacility.ExecuteNoResults(connectionStringName, "EndConversation", Parameter.Create("handle", handle));
}
Stored procedures:
CREATE PROCEDURE [dbo].[SendMessage] (
@initiatorService sysname,
@targetService varchar(255),
@contract varchar(255),
@messageType varchar(255),
@data varchar(MAX) = NULL,
@handle varchar(255) = null
)
AS
BEGIN
if @handle is null
begin declare @id uniqueidentifier BEGIN DIALOG CONVERSATION @id
FROM SERVICE @initiatorService
TO SERVICE @targetService
ON CONTRACT @contract
WITH ENCRYPTION = OFF, LIFETIME = 7200;
set @handle = cast(@id as varchar(255));
end;
send on conversation @handle message type @messageType (@data)
select @handle;
END
GO
CREATE procedure [dbo].[ReadMessage](@queueName varchar(255))
as
begin
declare @ch varchar(255)
declare @mt varchar(255)
declare @data varchar(max);
declare @dt DateTime;
set nocount on
declare @Sql nvarchar(max) = N'RECEIVE TOP(1) @h = conversation_handle, @messageTypeName = message_type_name, @Packet = message_body, @date = message_enqueue_time FROM ' + @queueName + ';'
EXECUTE sp_executesql @Sql, N'@h UNIQUEIDENTIFIER OUTPUT, @messageTypeName varchar(255) OUTPUT, @Packet VARCHAR(max) OUTPUT, @date datetime OUTPUT'
,@h = @ch OUTPUT
,@messageTypeName = @mt OUTPUT
,@Packet = @data OUTPUT
,@date = @dt output;
select * from (select @ch ch, @mt mt, @data [data], @dt [dt]) M for xml auto
end
GO
CREATE procedure [dbo].[EndConversation](@handle varchar(255)) as
begin
;end conversation @handle;
end
Finalmente, a seguir está o exemplo de um Thin Client, com um envio de mensagem e a rotina que faz o processamento das mensagens de retorno. Para cada tipo de ação criada, deve haver um tratamento específico. O construtor recebe, por injection (o Unity cuida disto) o storage e a classe que irá tratar as regras de negócio.
public class ClientService: ServiceBase, IClientService {
private readonly IReceiver receiver;
public ClientService(IStorage storage, IReceiver receiver)
: base(storage, true, Configuration.Requester.Service, Configuration.Executer.Service, Configuration.Contract,
Configuration.Requester.Message, Configuration.Requester.Queue) {
this.receiver = receiver;
}
public void RequestAction1() {
SendMessage(new MessageContent { Action = Actions.Action1});
}
public override bool ProcessMessage(Message message) {
var ser = new DataContractJsonSerializer(typeof (MessageContent)); MessageContent content; using (var ms = new MemoryStream(Encoding.UTF8.GetBytes(message.Contents))) {
content = (MessageContent) ser.ReadObject(ms); } if (content == null) return true;
try { switch (content.Action) {
case Actions.Action1: return receiver.ReceiveMessage(content, message.Date);
default: return receiver.Error(content.Action, ErrorCodes.NotImplemented, null);
}
}
catch (Exception ex) { return receiver.Error(content.Action, ErrorCodes.Exception, ex);
}
}
O executor não é diferente, como pode ser visto abaixo. Ele somente recebe a mensagem, faz algum tipo de ação de negócio específica e retorna os dados para o solicitante. Claro que isto é um código simplificado, já que em um código de produção é importante tratar todos os tipos de erros possíveis, evitando rollbacks da fila.
public override bool ProcessMessage(Message message) {
var ser = new DataContractJsonSerializer(typeof(MessageContent));
MessageContent message;
using (var ms = new MemoryStream(Encoding.UTF8.GetBytes(message.Contents))) {
message = (MessageContent)ser.ReadObject(ms);
}
if (message == null) return true;
var returnMessage = new MessageContent {Action = message.Action};
try {
switch (message.Action) {
case Action.Action1:
returnMessage.Data = MyBusinessRulesManager.ExecuteSomething(message).ToString();
break;
}
}
catch (Exception ex) {
returnMessage.Error = ex.Message;
}
SendMessage(returnMessage, message.Handle);
return true;
}
Bom, espero ter conseguido passar uma visão geral da arquitetura de Microservices que estamos utilizando. Claro que temos muitos outros cenários que fazem com que a complexidade desta arquitetura seja bem maior. Por exemplo, temos situações onde temos mensagens geradas em horários específicos ou que só podem ser executadas em horas úteis. Isto faz com que o Executor tenha toda uma lógica para armazenar as mensagens com agendamento de execução específica em outras filas. Mas tudo isto é feito com o fundamento que mostrei nesta série. Como sempre, fiquem à vontade para entrar em contato para tirar dúvidas ou conversar mais sobre este assunto. Até a próxima!
Arquitetura de Microservices utilizando o Microsoft SQL Service Broker – Parte 2
Publicado por Alexandre Valente em Desenvolvimento em 30/08/2015
Oi pessoal! Este post é continuação da série sobre a implementação de um barramento de microservices usando o SQL Server Service Broker (veja a primeira parte aqui).
O primeira passo é montar a infraestrutura no SQL Server. O barramento de microservices é baseado em filas, assim é necessário escolher um banco de dados para a criação das mesmas. Em tese, qualquer banco pode ser usado, mas recomendo a utilização de um banco criado especificamente para esta finalidade, para facilitar as tarefas de infra como backup, monitoração etc.
No nosso caso, criamos um banco novo, chamado, por exemplo, “MyMicroservicesBus”. Após a criação do banco, deve ser feito o comando abaixo, para que o Service Broker seja ativado no mesmo.
ALTER DATABASE MyMicroservicesBus SET ENABLE_BROKER
O próximo passo é criar as filas e contratos. Para quem não é muito familiar com os conceitos do SQL Server Broker, ver referência aqui. Recomendo também o livro “Pro Sql Server 2008 Service Broker”, bem completo. São necessárias duas filas, uma para servir de canal de comunicação da “Thin API” para o Executor (ExecuterQueue) e outra para que ele possa enviar as respostas de volta (InitiatorQueue). Para cada fila é necessário definir um contrato, que vai servir também para o versionamento das mensagens e um Service, para o roteamento de mensagens. Por último, não esquecer de dar as permissões de RECEIVE para os usuários apropriados. Um script completo é mostrado a seguir.
-- messages create message type [http://mydomain.net/services/myservice/requestMessageV1] Validation = None GO create message type [http://mydomain.net/services/myservice/responseMessageV1] Validation = None go -- contracts create contract [http://mydomain.net/services/myservice/contractV1] ( [http://mydomain.net/services/myservice/requestMessageV1] sent by initiator, [http://mydomain.net/services/myservice/responseMessageV1] sent by target ) go -- QUEUES create queue MyServiceInitiatorQueue with status = on go create queue MyServiceExecuterQueue with status = on go -- SERVICES create service MyInitiatorService on queue MyServiceInitiatorQueue ([http://mydomain.net/services/myservice/contractV1]) go create service MyExecuterService on queue MyServiceExecuterQueue ([http://mydomain.net/services/myservice/contractV1]) go -- permissions grant RECEIVE ON MyServiceInitiatorQueue to public go grant RECEIVE ON MyServiceExecuterQueue to public go
Uma vez que as filas estejam definidas, devemos decidir como as mensagens vão ser recebidas peles executores e clientes. Existem várias alternativas para isto, a mais simples seria usar stored procedures para processar mensagens de cada lado. No nosso caso, isto não atende pois temos regras de negócio complexas que devem ser executadas para cada mensagem, que estão implementadas em nosso Domínio e não faria sentido ou seria viável repeti-las em procedures. Assim precisamos de algo que seja capaz de chamar uma regra de negócio dentro do nosso ambiente transacional.
A segunda possibilidade é utilizar o Service Broker External Activator, que é uma ferramenta disponibilizada pela Microsoft para estes cenários. Ele fica “escutando” as filas e se encarrega de chamar um executável externo que, no nosso caso, seria um código em C#. Em nossos testes, funcionou perfeitamente nos nossos ambientes de desenvolvimento e homologação, mas qual a nossa surpresa ao ver que no ambiente de produção ele simplesmente não funcionou. Depois de muito pesquisar, descobrimos que ele não funciona em Clusters de SQL Server, que é exatamente o cenário usado no ambiente de produção do nosso cliente.
A terceira possibilidade, a mais complexa, é utilizar código CLR embutido dentro do SQL Server. Há várias versões do SQL Server é possível compilar uma DLL e registrá-la para uso dentro de um database como se ela fosse uma stored procedure. Esta foi a alternativa escolhida para nosso cenário.
Só recapitulando o procedimento para incluir um código CLR no SQL Server: primeiro, é necessário criar um projeto com uma classe estática e um método estático, que vai ser o ponto de entrada para a chamada no SQL Server, decorado com o atributo Microsoft.SqlServer.Server.StoredProcedure. Depois este assembly deve ser registrado no database e finalmente as queues devem ser modificadas para acionar este método quando uma mensagem chegar. Um exemplo de código CLR e script estão a seguir. Lembrando que caso o assembly não seja assinado com um certificado confiável para o servidor onde está o SQL Server, é necessário baixar o nível de confiança do banco (primeira instrução do script abaixo). Como nossos assemblies não estavam assinados, optamos por fazer isto. Esta decisão deve ser tomada com responsabilidade, pois este comando vai aumentar a vulnerabilidade do banco de dados.
using Microsoft.SqlServer.Server;
namespace MyNamespaceInAssembly {
public static class StoredProcedures {
[SqlProcedure]
public static void ProcessMessages() {
Domain.Services.ProcessMessages();
}
}
}
Script:
-- Allows unsigned Assemblies ALTER DATABASE ServiceBroker SET TRUSTWORTHY ON GO -- Register Assemblies CREATE ASSEMBLY MyServiceThinClient from 'c:\myservice\ThinClientProcessor.dll' WITH PERMISSION_SET = UNSAFE go CREATE ASSEMBLY MyServiceExecuter from 'c:\myservice\ExecuterProcessor.dll' WITH PERMISSION_SET = UNSAFE go -- procedures CREATE PROCEDURE ProcessMessagesThinClient AS EXTERNAL NAME MyServiceThinClientAssembly.[MyNamespaceInAssembly.StoredProcedures].ProcessMessages go CREATE PROCEDURE ProcessMessagesExecuter AS EXTERNAL NAME MyServiceExecuterAssembly.[MyNamespaceInAssembly.StoredProcedures].ProcessMessages go -- permissions grant execute on ProcessMessagesThinClient to public go grant execute on ProcessMessagesExecuter to public go -- activations alter queue MyServiceInitiatorQueue with activation( procedure_name = ProcessMessagesThinClient, MAX_QUEUE_READERS = 1, status = on, execute as self) go alter queue MyServiceExecuterQueue with activation( procedure_name = ProcessMessagesExecuter, MAX_QUEUE_READERS = 1, status = on, execute as self) go
Por enquanto é só pessoal. Na parte 3 vou detalhar melhor o código do ProcessMessages, tanto do ThinClient quanto do Executor. Se tiverem dúvidas específicas, podem entrar em contato. Até a próxima!
Arquitetura de Microservices utilizando o Microsoft SQL Service Broker – Parte 1
Publicado por Alexandre Valente em Desenvolvimento em 01/08/2015
Olá pessoal, vou iniciar uma série de posts mais técnicos desta vez. Como mencionei no post anterior, estivemos analisando o uso do Microsoft SQL Server Service Broker como uma alternativa para implementação de Arquitetura de Microservicess. Aproveitando uma necessidade de um de nossos clientes, conseguimos definir e implementar um barramento de microservices com sucesso, que já está em execução em ambiente de produção! Nesta série de posts vou detalhar a arquitetura utilizada, tentando mencionar os desafios que enfrentamos e as soluções adotadas. Espero que sirva de apoio para outros desenvolvedores se aventurando por esta linha.
Inicialmente um pouco de contexto. Em um de nossos clientes, da área financeira, possuímos um grande sistema .NET, em operação há mais de 20 anos. Apesar dele ser relativamente bem estruturado (separação de camadas, mapeamento objeto-relacional com nHibernate, interfaces MVC etc.), ele acumulou, por todo este tempo de evolução, uma infinidade de regras de negócio para cada uma das áreas atendidas. Por ser um sistema central da empresa, praticamente todas as operações passam pelo mesmo e ele é integrado à vários outros, por diversas formas de comunicação. Assim, temos cada vez mais dificuldade para evoluí-lo e mantê-lo, já que sua arquitetura monolítica faz com que testes de integração e homologação sejam extremamente complexos e demorados. É com grande dificuldade que conseguimos manter um ritmo saudável de trocas de uma metodologia ágil, pois o tempo de homologação de usuários quase que inviabiliza nossas janelas semanais.
Outro grande problema de nosso sistema monolítico é a escalabilidade. Com o aumento de demanda, não temos opção a não ser aumentar o número e capacidade de máquinas, pois o sistema tem que ser replicado por inteiro. gerando aumento de custos e complexidade de infra-estrutura.
Este seria um dos típicos problemas resolvidos por um sistema que utiliza uma arquitetura de microservices. Cada área de um sistema de grande porte seria implementada por um serviço independente, que usa um barramento de mensagens para comunicação entre si (ver figura a seguir). Desta forma, a manutenção ou evolução de uma área não afetaria outras, tendo seu próprio ciclo de desenvolvimento independente.

Porém, é raro termos o luxo de projetarmos um sistema do zero já incorporando este tipo de arquitetura. Então, nosso primeiro desafio foi achar uma maneira de fazer com que um sistema monolítico como o nosso pudesse utilizar microservices sem que ele tivesse que ser refeito do zero. A solução que encontramos está mostrada na figura a seguir. Inicialmente, isolamos uma área que possa ser implementada como um serviço isolado (A). Depois, quebramos este bloco em duas porções: uma pequena interface de comando e recepção de resultados (“Thin” API); e o módulo que implementa os executores de ações e regras de negócio específicas (B). Entre estes blocos, incluímos o suporte ao envio e recepção de mensagens, para que a API se comunique com o executor através do barramento de microservices (C).

Desta forma, conseguimos alguns benefícios da arquitetura de microservices: 1) o executor é completamente isolado do sistema principal, podendo ser evoluído de maneira independente; 2) a execução de atividades passa a ser feita de forma assíncrona, liberando recursos para o sistema e permitindo a escalabilidade horizontal dos executores. Se conseguirmos isolar cada área desta forma poderemos, a longo prazo, quebrar nosso sistema monolítico em vários microservices, chegando bem próximo de um sistema que fosse projetado do zero para esta arquitetura.
Pode-se argumentar que outras arquiteturas poderiam gerar benefícios similares. Uma alternativa, por exemplo, seria fazer uso de componentes intercambiáveis. Embora isto garantisse o isolamento da área de negócio, não resolveria por completo a questão da substituição em produção. Com microservices, podemos parar um dos executores de serviço, ou mesmo todos eles e todo o sistema continua funcionando normalmente (as mensagens simplesmente se acumulam, sendo processadas posteriormente quando o serviço for restabelecido). No caso de componentes, seria muito mais complexo de resolver este cenário, pois há um acoplamento direto entre o mesmo e o sistema; se o componente parar o sistema também para. Com componentes também não teríamos solução trivial para o problema de escalabilidade.
Outra alternativa seria o uso de webservices tradicionais, baseados em SOAP ou outro protocolo. Webservices simplificam o problema da substituição em produção, pois podemos ter um cluster de servidores, com vários em paralelo, e ir substituindo aos poucos, com o uso de versionamento. Eles resolvem também o problema de escalabilidade, pois são de menor porte e podemos aumentar o cluster conforme necessário. O grande problema de webservices é a latência que existe para as chamadas de regras de negócio, já que eles normalmente se encontram em outros servidores. Para ações muito frequentes, em operações comuns do sistema, poderíamos ter uma demora excessiva para a execução, afetando o usuário. E operações assíncronas em sistemas web chamando webservices são extremamente difíceis de serem implementadas.
Analisando estes e outros cenários, a arquitetura de microservices parece ser a mais adequada. Da mesma forma que um webservice, ela separa a camada de negócios, permitindo escalabilidade e isolamento. E é tão rápido quanto um componente, já que a sua “Thin” API reside dentro da aplicação. É claro que o lado negativo é que todas as operações, que antes eram síncronas, passam a ser assíncronas. Este é o maior limitador, já que é necessário reimaginar o comportamento do sistema considerando que as ações não são mais imediatas, mofidifcando a usabilidade do mesmo.
Para a implementação do nosso barramento de serviços, foi considerado o uso vários produtos, open source e comerciais. O RabbitMQ foi uma das alternativas que foram melhor avaliadas. No entanto, no final, a escolha foi o Microsoft SQL Server Service Broker. As razões foram a facilidade de se montar um barramento de serviços simples e o fato dos nossos sistemas já o usarem o SQL Server como DBMS, o que simplificou bastante nossa infraestrutura.
Bom, por hoje é só. Em breve devo detalhar a parte técnica da solução, desde a implementação das filas de mensagens e processadores até o processo de ativação de executores. Até a próxima!
Novidades!
Publicado por Alexandre Valente em Desenvolvimento, White Fox em 07/06/2015
Olá pessoal, há quanto tempo!! :)…. Estive ontem no Visual Studio Summit 2015 e continuo achando este o melhor evento da Microsoft para desenvolvedores. Este ano esteve especialmente bom já que temos muitas tecnologias e plataformas a caminho, tais como o Visual Studio 2015, o ASP.NET 5 e o C# 6.0. Foi bom poder conversar como os early-adopters e colher opiniões sobre o que temos de bom em cada novidade destas. Sem entrar muito em detalhes, é suficiente dizer que fiquei positivamente impressionado, fazia tempo que não via a Microsoft engajada em disponibilizar tantos recursos para os desenvolvedores. E é perceptível também o esforço em começar a integrar os produtos Microsoft com as outras plataformas, como o Visual Studio Code para Mac e Linux e nos novos recursos de integração do Visual Studio 2015 RC com o melhor do mundo open source, tais como Node.js NPM, Grunt e Bower. Para quem ainda não baixou o Visual Studio 2015 RC, recomendo fazer isto logo, vale a pena no mínimo para se preparar para estas mudanças.
Na White Fox, continuamos firmes na nossa transição de desenvolvimento MVC clássico para um modelo baseado em MVC REST APIs e uma interface rica baseada em AngularJS. Praticamente todos os nossos sistemas já possuem telas desenvolvidas com esta tecnologia e novos sistemas estão sendo feitos exclusivamente neste formato. É cada vez mais comum também expormos estas APIs para interfaces desenvolvidas para dispositivos móveis, o que faz com que nossas APIs tenham que ser desenvolvidas com um agnosticismo completo com relação às interfaces que a vão utilizar. Se por um lado isto é uma boa prática, por outro significa migrar centenas de telas de legado para este novo formato, o que muitas vezes é bem custoso.
Na parte de ORM, continuamos sem um norte claro. A maior parte de nossos sistemas continua usando a versão antiga do nHibernate com o Castle ActiveRecord. Porém a idade está começando a pesar nesta plataforma, começando a tornar difícil algumas evoluções que precisamos fazer. Fizemos algumas tentativas de migração para o Entity Framework com relativo sucesso usando o Entity Framework 6. Porém, como nossos sistemas são muito complexos (centenas de entidades), o esforço de mapeamento é considerável, e temos bugs sérios no designer do EF6 com relação a defaults de banco de dados, o que torna a atividade ainda mais complicada. E, para detonar de vez este cenário, o EF7 vai remover o modelo “database-first”, o que inviabiliza o que fizemos até agora.
Esta questão do EF7 me intriga. Conversando ontem com outros desenvolvedores, percebi que muitos têm problemas similares. O uso do EF com sucesso acontece quando o sistema é novo e tem um único “dono” para banco de dados. Porém isto não é comum na nossa realidade (e, pelo que vi, de muitas outras), pois o banco é compartilhado entre vários sistemas legados e não há um único responsável pela evolução do mesmo. Neste aspecto, até a proposta da Microsoft para substituir o modelo database-first pelo code-first com migrations não resolve, pois temos alterações que não viriam do EF. Parece que não teremos alternativa a não ser codificar os objetos na mão (e voltamos 10 anos no tempo!!). Pelo menos o uso do Power Tools para o EF deve ajudar um pouco. E estamos de olho em ferramentas de terceiros, como as da DEVART, que também podem ser uma alternativa. Mantenho vocês informados da nossa evolução.
Outro tópico muito interessante ontem foi o relativa à Microservices. Percebi que outras pessoas estão com o mesmo problema que o nosso, que é manter a agilidade em sistemas de grande porte, onde o processo de deploy é amarrado por inúmeros problemas: demoras em homologação, sistema monolítico etc. Microservices podem ser uma solução para isto, a ideia é decompor o sistema em componentes de serviço e com isto podermos substituir um ou outro sem afetar a aplicação como um todo. Em teoria, a ideia é boa, mas, na prática, ainda não temos uma plataforma definida para implementarmos isto. As implementações de Microservices normalmente fazem uso de filas de mensagens, o que gera problemas para sistemas que exigem uma resposta síncrona. Além disto ainda temos que escolher uma boa plataforma para implementar este barramento de serviços/mensageria. O Microsoft Azure tem uma implementação interessante, porém ele não é uma opção para sistemas internos. Estamos analisando possibilidades como o Service Broker do próprio SQL Server ou soluções open source como o RabbitMQ, vamos ver como fica isto nos próximos meses.
Até a próxima!
